Prévoir une attaque est souvent un processus chronophage et méticuleux. Évidemment parce qu’il faut chercher un maximum d’information à propos de la cible convenue, mais aussi parce qu’il faut prévoir le dérouler théorique de l’opération, comment procéder le plus anonymement possible une campagne de phishing, comment pouvoir déposer efficacement les charges virales employées, comment assurer la communication avec notre système de contrôle des implants et assurer la persistance des accès. Le tout en préservant la sécurité des données de l’entreprise qui a engagé la mission et la discrétion des opérateur pour un tout aussi réaliste que possible. Dans cet article nous allons explorer le cœur d’une mission Red-Team, l’infrastructure qui sera déployée.
Merci d’avance à @Eban pour les schémas, n’hésitez pas à aller regarder son travail !
Quelques considérations
Chaque étape de la “cyber killchain” possède ses spécificités, et par conséquent des TTPs (“Tactics, Techniques and Procedures”) propres. Ainsi, l’infrastructure doit suivre quelque soit la phase dans laquelle nous nous situons et s’adapter pour fournir la simulation la plus réaliste possible d’une attaque, et de surcroît la plus grande marche de manœuvre possible pour les opérateurs. En revanche, chacune de ces étapes a ses exigences, que ce soit en terme de discrétion, de communications, d’interactions avec les humains derrière notre cible (en raison des TTPs liées et aux outils qui seront utilisés). On doit donc répartir, en fonction de ses besoins, l’investissement en viabilité, efficacité et rapidité. Néanmoins il est presque, si ça ne l’est pas, impossible de combiner entièrement ces exigences. En outre, communiquer de manières efficaces (que ce soit en difficulté d’être bloqué ou en quantité de données qu’il est possible d’exfiltrer) peut se baser sur des protocoles précisément peu rapide (comme l’utilisation de services web externes), ou bien peu viable comme DNS qui se base sur UDP, beaucoup plus rarement TCP (perte de paquets possible et assez facilement détectable en cas de quantité de données conséquente). Pour mieux imager cela, prenons plusieurs exemples. Pour le maintient d’accès, il est sûrement préférable de limiter l’efficacité de la communication et de privilégier la viabilité de celle-ci. En revanche lors de l’exploitation active, on voudrait avoir un mixe entre viabilité et efficacité pour avoir un certain confort. Là où, pour l’accès initial nous voudrions nous concentrer sur la rapidité d’exécution et donc sur l’efficacité, pour rapidement obtenir un accès stable à l’environnement cible.
Il faut de plus prévoir d’autres contraintes issues de constats simples:
- La discrétion des opérations devra d’une certaine façon être assurée par notre infrastructure. La quantité d’informations que les attaquants laisseront voir, par exemple, devra être minimiser pour empêcher la blue-team de trop rapidement se rendre compte de l’attaque. Maximiser la diversité d’IPs ou de domaines engagés, de méthodes de communications, pour mieux se fondre dans le trafic et se cacher des défenseurs.
- Malgré cela, il faut tout de même anticiper les cas qui mettraient en péril la mission. En cas de découverte de domaines, de serveurs servant aux attaquants. Il faut ainsi avoir la capacité de rapidement se remettre d’un tel évènement. Ou si cela est impossible, segmenter un maximum l’infrastructure (en ne faisant pas cumuler les rôles d’un même serveur, par exemple) afin d’éviter qu’un seul élément provoque la fin de l’attaque.
- Enfin, les serveurs loués, ou les services utilisés devront correctement être capable de sécuriser les données qui vont être exfiltrées. Une entreprise engage une mission Red-Team pour éviter une attaque qui causerait la fuite de données sensibles, et non provoquer ladite fuite !
L’une des entités les plus importante dans notre infrastructure est le “Command & Control” qui assure la communication avec les utilisateurs compromis, et permet la continuation de l’attaque une fois l’environnement ciblé atteint.
Command & Control
Le terme de “Command & Control” (aussi abrégé C2) est originellement un terme militaire désignant un modèle organisationnel et structurel employant un certain nombre de ressources différentes pour remplir un objectif précis. L’emploi qu’il se fait de ce terme en est légèrement dérivé et désigne un ensemble d’outils permettant d’assurer la communication et le contrôle de machines compromises. Même s’il subsiste une idée commune et générale entre ces deux définitions.
On peut dès lors se rappeler que nous sommes assez aisément capable de produire des programmes permettant d’avoir une exécution de commandes sur une autre machine (les classiques et très connus “reverse shell”). Nous avons perfectionné ces outils pour pouvoir optimiser différents mécanismes de post-accès. Prenez Metasploit par exemple qui introduit des fonctionnalités comme l’analyse de vulnérabilités en vue d’escalade de privilèges, ou encore le déploiement de “proxysocks” permettant des mouvements latéraux plus aisés. Nous souhaitons désormais aller plus loin, en commençant par chercher les défauts de ces implémentations, puis en incluant certains des aspects que nous avons vu dans la section précédente. Lorsqu’un accès est obtenu avec le système de Metasploit (nommé meterpreter, les autres aussi ont des noms spécifiques) la fermeture du programme client entraîne la fermeture du programme serveur, ainsi nous perdons notre accès. De plus, il n’est pas confortable de l’utiliser dans le cas du contrôle de plusieurs implants. En effet, il faut à chaque fois relancer l’écoute de potentielles nouvelles charges déclenchées. De surcroît, l’usage le plus commode consiste en l’usage d’un canal de communication TCP ce qui très facilement détectable avec Wireshark par exemple.
C’est sur ces considérations (et d’autres encore) qu’ont été pensés la plupart des C2s modernes comme CoblaltStrike (beacons), PowerShellEmpire (agents), Covenant (grunts), SharpC2 (drones), dnscat/dnscat2, Mythic (agents), koadic (zombies), bruteratel, PoshC2 (la légende raconte qu’il a même été utilisé par APT33) pour n’en citer que quelques uns. Le fonctionnement général de ces derniers se base sur un système très simple qui offre une immense souplesse opérationnelle, un “teamserver” et un client qui sont indépendant. Le premier assure un certains nombre de choses:
- La communication avec les implants au travers de plusieurs protocoles simultanément.
- La préservation des communications même sans qu’aucun client (opérateur) n’y soit connecté.
- L’utilisation des capacités de post-exploitation disponibles.
Et encore bien d’autres. Aussi, il expose un accès pour le client, généralement en ouvrant un port spécifique.
Le client lui, est l’interface qui permet à un opérateur d’user de toutes les capacités de son C2. Il existe plusieurs schémas: soit le client demande à l’opérateur les informations permettant de se connecter au “teamserver” (l’ip où il faut se connecter, le port, etc); soit le “teamserver” ouvre une interface web sur laquelle les opérateurs se connectent directement.
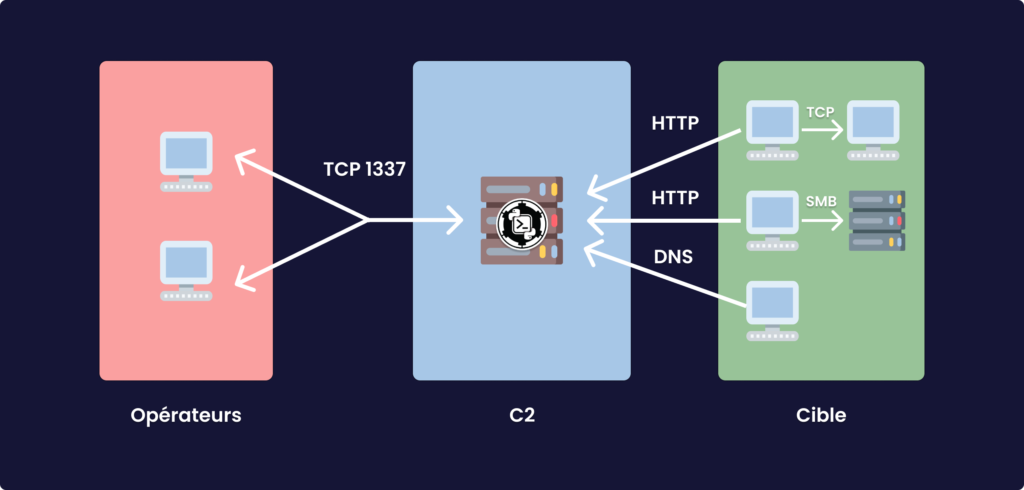
Cette architecture nous donne donc un grand nombre de possibilités, multiplier les serveurs de contrôle, pouvoir établir une hiérarchie et des rôles spécifiques en fonction de la structure dans laquelle ils sont utilisés, pouvoir aisément segmenter l’infrastructure… Usuellement, les fonctions de post-accès sont assez commune aux différents C2, comme la capacité d’exécuter du PowerShell avec PowerPick (si ça vous dit rien, j’ai écris un article sur le sujet), ou encore l’exécution d’Assembly .NET en mémoire (via la Réflexion pour les C2 usant beaucoup de C# par exemple, là aussi si cela vous est inconnu regarder la section programmation du blog). Ce qui diffèrent en revanche, sont les capacités de mouvement latéral, comme le C2 pair-à-pair (i.e, la capacité qu’ont les implants à se lier entre eux pour créer un réseau de communication, ainsi le serveur de contrôle n’est pas constamment interrogé), et les systèmes de communications qui sont implémentés. Les communications avec les machines compromises peuvent se faire au travers des techniques aussi diverses que variées:
- Connexion TCP directe (le cas du “reverse-tcp”) mais rarement utilisée car peu discrète, le tunnel de communication est synchrone.
- Protocoles Webs avec HTTP(s) par exemple, ce qui a pour intérêt de simuler un trafic légitime, certains C2 vont plus loin en cachant les commandes dans le contenu des pages dont on fait la requête qui sont construites pour être légitime (c’est le cas de TrevorC2). C’est le protocole HTTP(s) qui constitue la méthode la plus répandue. Cette méthode est dite asynchrone, le malware fait des appels au C2, après un intervalle de temps précis (il est nécessaire de le garder relativement élevé pour être discret).
- Autres protocoles comme SMTP, FTP ou DNS (pour le premier, on a vu APT28 l’utiliser, pour le troisième on peut citer CobaltStrike ou bien sûr dnscat).
- Au travers des services Web : dropbox, OneDrive, Outlook, github, reddit voir même Twitter (c’est le cas de PowerShell Empire, et du C3 de F-SecureLabs, C3 pour Custom Command & Control il permet entre autres de déployer des canaux de communications ésotériques).
- Pour ce qui est du C2 paire à paire, tout ce qui permet de cacher son trafic est utile, ouvrir un port TCP, utiliser les
NamedPipeSMB, LDAP (les deux premiers sont très souvent utilisés, LDAP quant à lui peut être vu avec C3) ou même RDP.
Globalement il s’agît de jouer avec les protocoles disponibles pour mieux se cacher et rester silencieux, il n’est ainsi pas exclu de se cacher dans des protocoles aussi exotiques que ICMP. Les capacités des différents C2 existant peuvent être consultées ici (version actualisée). Attention cependant, pour des C2s comme CobaltStrike ou PowerShell Empire, leur comportement peut être modifié grâce à des profiles malléables, pour les autres, il faut modifier le code!
En plus des différents moyens de communication, il peut être intéressant de jouer sur d’autres facteurs pour dissimuler et sécuriser son trafic, notamment avec la forme de ce dernier: en utilisant du chiffrement, de la stéganographie qui a été utilisée par APT29 par exemple, et beaucoup d’autres que vous pouvez retrouver ici.
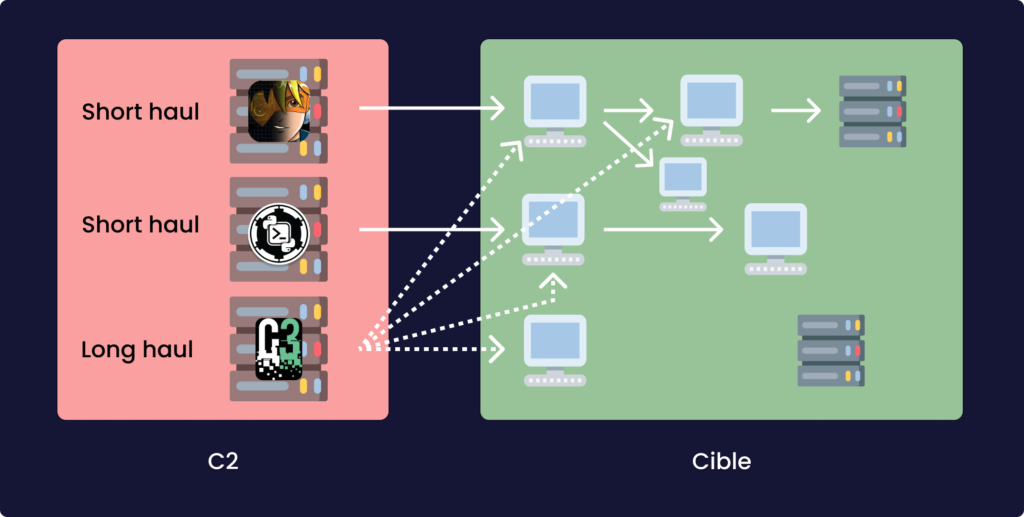
Les serveurs C2s qui seront utilisées sont souvent divisées en fonction des tâches à accomplir, en particulier vous trouverez dans la plupart des documentations (y compris celle de CobaltStrike) les serveurs dis “short-haul” et “long-haul”. Traduit littéralement “court-terme” et “long-terme”, le premier désigne un serveur C2 dédié aux opérations actives (exploitation de l’environnement), le deuxième est dédié à la persistance dont les implants communiqueront avec un très haut délai -Raphael Mudge, le créateur de CobaltStrike recommande 24h entre les checkin -i.e le temps d’intervalle qui sépare les communications entre le C2 et le malware-. Ils doivent être extrêmement discret car c’est eux qui permettent à l’opération de tenir dans la durée. Je dois ajouter cependant que dans le cas de Cobaltstrike, le processus est vraiment facilité car le client possède la capacité de se connecter à plusieurs “teamserver” en même temps. Les serveurs “short-haul” sont voués à être découvert et potentiellement changés. Il ne faut donc pas hésiter à multiplier le nombre de ces serveurs pour pouvoir créer une diversité en terme de domaine et d’IPs qui rendra l’ensemble des communications plus discrètes.
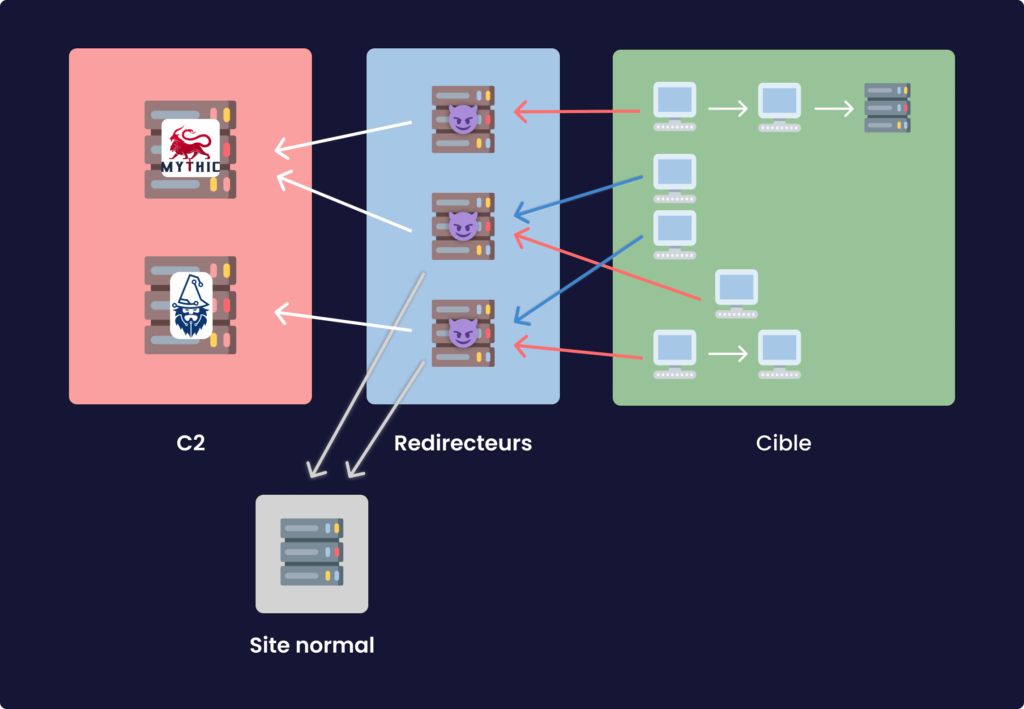
Cependant pour éviter à avoir remplacer les serveurs découvert, et optimiser la discrétion il faut concevoir une nouvelle entité qui aura un rôle presque aussi important que celui du C2.
“Redirecteurs”
Pour l’instant nous avons une entité qui permet de contrôler les machines compromises et qui de surcroît assure une certaine discrétion. Problème, lorsqu’un nouvel implant se connecte à notre C2, c’est ce dernier qui sera directement contacter. Or si un membre de la Blue-Team intercepte notre communication et remontre à notre serveur, il en déduira sûrement qu’il s’agît d’une potentielle attaque. Il nous faut donc trouver un moyen d’avoir des relais qui peuvent être découvert (et donc facilement remplaçable) sans pour autant compromettre les C2s. Pour cela il faudra s’accorder avec la méthode de communication choisie (il est assez évident que pour certaines méthodes, il n’existe pas de relais). Il en existe globalement de 2 types, les redirecteurs HTTP et DNS, je ne vais traiter ici que le premier.
3 méthodes existent pour créer des redirecteurs HTTP(s). Les deux premières sont assez simples et naturelles. Avec socat:
socat TCP4-LISTEN:80,fork TCP4:<ADRESSE DE VOTRE C2>:80
Mais aussi avec iptables:
iptables -I INPUT -p tcp -m tcp --dport 80 -j ACCEPT iptables -t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to-destination <ADRESSE DE VOTRE C2>:80 iptables -t nat -A POSTROUTING -j MASQUERADE iptables -I FORWARD -j ACCEPT iptables -P FORWARD ACCEPT sysctl net.ipv4.ip_forward=1
Ces méthodes ont l’avantage d’être simple et rapide à mettre en place, mais elles posent un problème. Si effectivement les adresses de nos C2 sont cachées, cela n’empêche les équipes de réponse à incident d’accéder au contenu des serveurs puisque aucun filtrage n’est effectué. Pour répondre à cette problématique on peut utiliser apache et son extension mod_rewrite qui est un module permettant d’effectuer des tests conditionnels sur les requêtes qui sont faites sur le serveur web. Voilà un schéma pour illustrer cette idée:
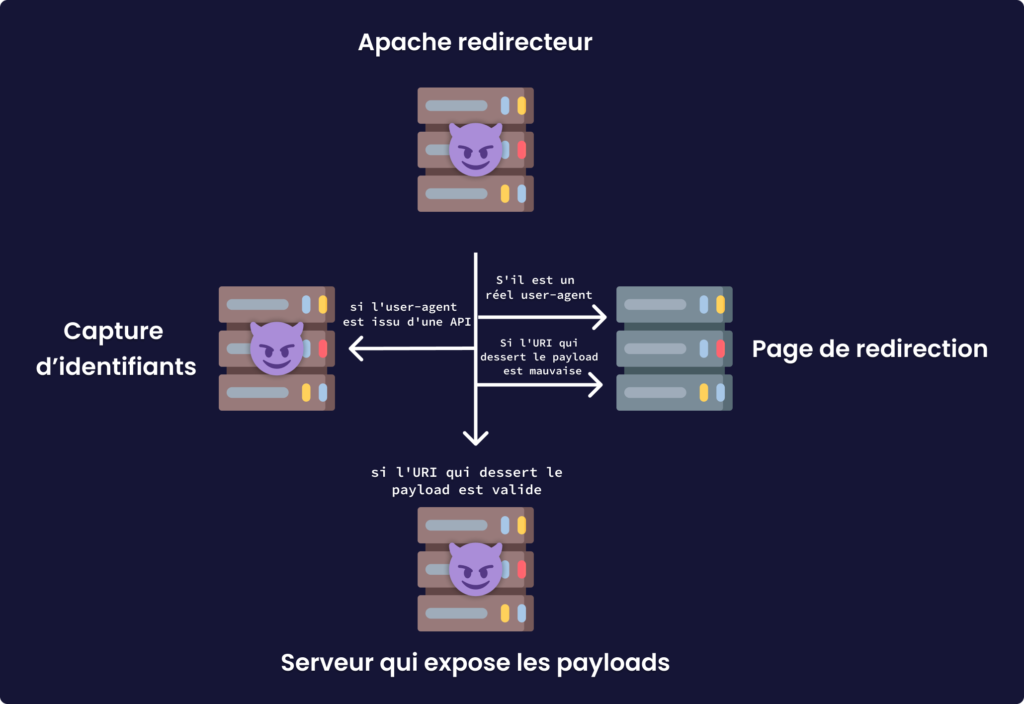
Avant d’installer le module, il faut éditer la configuration de apache (/etc/apache2/apache.conf) et changer un paramètre dans le bloc suivant (si vous choisissez évidemment /var/www comme étant le répertoire qui sera exposé par apache):
<Directory /var/www/>
Options Indexes FollowSymLinks
AllowOverride None
Require all granted
</Directory>
le paramètre sera changé AllowOverride None pour AllowOverride All. Une fois cela fait, on peut désormais installer les modules nécessaire avec:
sudo a2enmod rewrite proxy proxy_http
Et redémarrer le service apache:
systemctl restart apache2
Ensuite il faut créer les règles de tests. Pour cela il faut déjà inclure dans notre profil malléable les urls qui seront utilisé pour les différentes requêtes que l’implant fera: stage, GET, POST … ainsi que le “user agent” qui sera utilisé. Les règles utilisées par mod_rewrite sont des Regex couplées avec une syntaxe un peu particulière. En effet les tests sont effectués sur des variables générées lorsqu’une requête est effectuée. Le domaine sera désigné par la variable %{HTTP_HOST}, l’uri par %{REQUEST_URI}, les paramètres qui y seront ajoutés par %{QUERY_STRING}, le user-agent par %{HTTP_USER_AGENT}, l’ip de requête par %{REMOTE_ADDR} et encore bien d’autres que vous pourrez retrouver ici. Pour effectuer un test on utilise l’instruction RewriteCond qui est suivie de la variable sur laquelle on effectue le test. Ensuite on indique par ^ le test regex. On termine avec un petit flag qui modifie encore le comportement. Vous pouvez évidemment cumuler les tests. Pour cela on retourne à la ligne et on replace un test (sur une autre variable par exemple). Ces deux tests à la suite seront considérés par apache comme un AND par défaut, si vous souhaitez un comportement autre, il faudra ajouter le flag [OR] à la fin du test. Maintenant que nous avons effectué notre test il faut donc construire la redirection qui sera effectuée en fonction de la validation ou non du test. Pour cela on utilise l’instruction RewriteRule.
Pour terminer la configuration, on modifie le fichier .htaccess à la racine du site en ajoutant en premier lieu RewriteEngine On, et en plaçant vos tests à la suite. De plus, pour activer le support du SSL, il faut modifier le contenu du fichier /etc/apache2/sites-available/000-default-le-ssl.conf.
En vue d’une économie de temps certaine, il existe un outil permettant d’automatiser ce processus: cs2modrewrite. Créé par Joe Vest lorsqu’il était à SpecterOps (et oui encore eux) il prend en argument 3 paramètres, -i qui est le chemin vers le profile malléable, -c qui est l’hôte http(s) du c2 (au format http(s)://domain.com ou http(s)://ip), -r l’adresse de redirection au même format que le paramètre précédent. Le résultat doit être placé dans le .htaccess, mais avant n’oubliez pas de regarder pour de potentiels erreurs.
A noter qu’il est également possible de faire des redirecteurs HTTP(s) avec d’autres technologies comme par Nginx dont je n’ai pas parlé car je n’ai pas du tout d’expérience avec, ou encore AWS lambda, dont je ne connais que les très grandes lignes alors en attendant que je m’y attarde et édite cette article je vous invite à lire celui de @_xpn_ (en anglais) https://blog.xpnsec.com/aws-lambda-redirector/.
Les redirecteurs sont une unité extrêmement puissante par les possibilités qu’ils offrent.
Serveurs de Phishing
J’entends ici par Phishing tout ce qui est attrait avec une interaction avec les utilisateurs profitable offensivement parlant : accès initial par mails, capture d’identifiant voir même relais de ces derniers. Commençons par le plus simple, les serveurs SMTP. Le serveur SMTP permet l’envoie de mails en vu d’une campagne de (spear) phishing, contrairement à ce qu’on pourrait intuitivement penser, lorsque les mails sont bien faits, et envoyer au bon moment, les résultats sont généralement très probants. Pour en installer un, on peut utiliser opensmtpd ou postfix si on veut tout faire à la main, sinon des solutions déjà faite comme poste.io, iredmails. Une fois cela terminé, vous pourrez utiliser des outils comme sendemail ou cobaltstrike pour envoyer vos mails. Pour vous simplifier la tâche, on peut également installer des frameworks dédiés au phishing comme gophish. Son installation est simple mais il faut installer plusieurs dépendances comme go, ce qui peut ajouter du travail en vu d’un déploiement automatique.
Pour un accès initial on peut également utiliser des redirecteurs apache pour optimiser la livraison des charges malveillantes avec mod_rewrite. Par exemple, si vous voulez restreindre l’accès en fonction du système d’exploitation pour éventuellement détourner de rare personnes sur Linux, vous pouvez. Si vous voulez restreindre les accès en fonction de l’heure et du user-agent, vous pouvez. Ces possibilités sont utiles pour maximiser la difficulté de potentiels défenseurs d’analyser trop en profondeur notre infrastructure. Il y a bien d’autres astuces que vous pouvez utiliser, @bluescreenofjeff en a dédié une petite série (en anglais) qui commence à cet article.
Il faut ajouter, pour maximiser l’anonymat des opérateurs et des infrastructures en jeu, des redirecteurs (même si l’utilisation de ce terme est un peu extrapolée) SMTP qui auront pour but d’effacer certains headers compromettant. Ainsi ces redirecteurs sont tout comme les redirecteurs HTTP(s)/DNS, c’est à dire qu’ils doivent être facilement remplaçable.
On peut également étendre l’utilisation du mot Phishing pour désigner les résultants d’une interaction directe avec l’un des utilisateurs de l’environnement ciblé. En effet, il existe un nombre très conséquent d’attaques qui vise particulièrement les utilisateurs. Lorsqu’on a besoin d’obtenir de nouveaux identifiants, et qu’on identifie un moyen de forcer l’authentification d’un compte à une ressource externe, serveur SMB, serveur HTTP qui nécessite l’authentification NTLM, (JEA qui exhibe une Cmdlet comme Invoke-WebRequest, un partage accessible à des utilisateurs dans lequel on peut placer un fichier scf, l’exploitation des nodes ADIDNS…) il peut être utile de réserver ce rôle à un unique VPS. A noter ici qu’il est également possible d’utiliser des redirecteurs vers ce genre de serveur.
Autres serveurs
Les idées qui seront développées ici font sans doute partie des moins importante comparées à celles que nous avons vu au dessus.
En plus de tout cela, vous pouvez encore ajouter deux types de serveurs. Le premier accueil une multitude de protocole destinée à transférer les malwares vers les victimes de de votre Phishing par exemple, ou bien de vos dropper. Comme je l’ai dis vous pouvez user de différents systèmes pour livrer vos charges : un serveur web, FTP ou même SMB. Ces derniers seront d’autant plus efficace si vous préparez un système qui permet de choisir aléatoirement le serveur qui sera contacté, et même le type de payload qui sera utilisé.
Beaucoup plus accessoire, vous pouvez déployer des serveurs dédiés aux DevOps, j’y reviendrais dans un article c’est sure. L’idée de ces derniers est de randomiser les outils/payloads qui seront utilisés. Cela à plusieurs avantages: d’un point de vue professionnel, cela assure l’individualité des outils et malwares ce qui ajoute du réalisme à l’engagement, mais aussi donne des artefacts forensiques moins générique, en d’autres termes renforce notre discrétion; d’un autre côté plus pratique, cela peut aider à fournir des moyens simples et efficaces pour le contournement d’antivirus (même si dans les faits ils ne sont pas vraiment dérangeant). Cela dit, ce composant précis n’a pas besoin d’être individualisé avant chaque opération, car son installation est lourde de configuration.
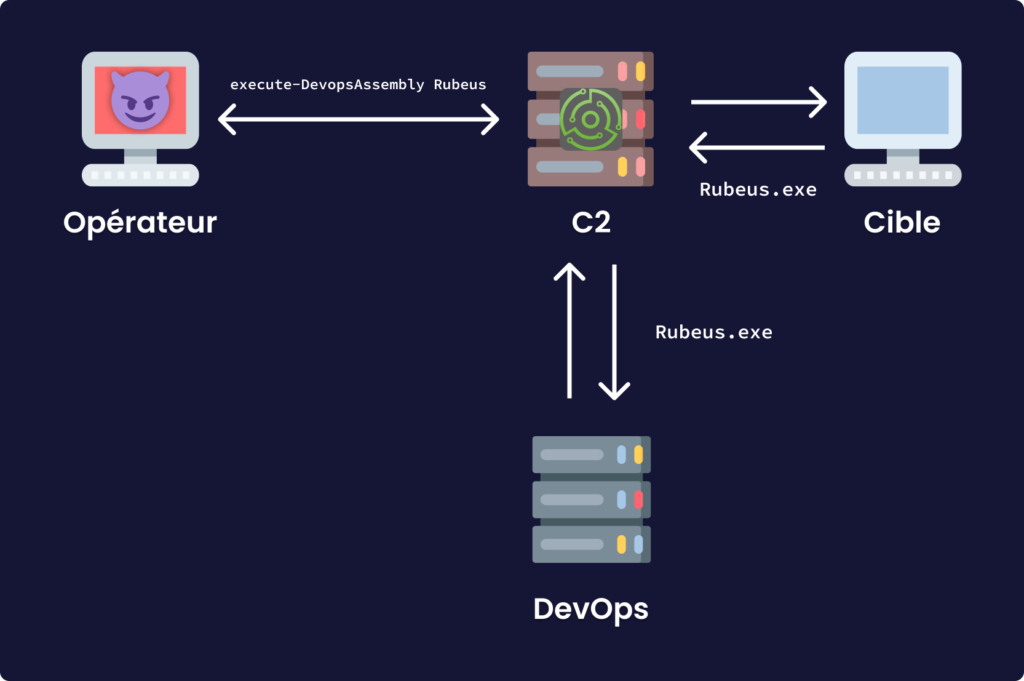
Exemples
Maintenant qu’on a définit les éléments génériques d’une infrastructure, il ne reste plus qu’à évaluer les besoins de votre mission pour en adapter les composants (il va de soit qu’il est inutile de déployer ce genre d’architecture pour un prolab de HackTheBox, sauf peut-être le C2) ! Mais pour vous donner une petite idée de comment certaines équipes Red-Team gèrent leur infrastructure, voilà comment praetorian s’organise:
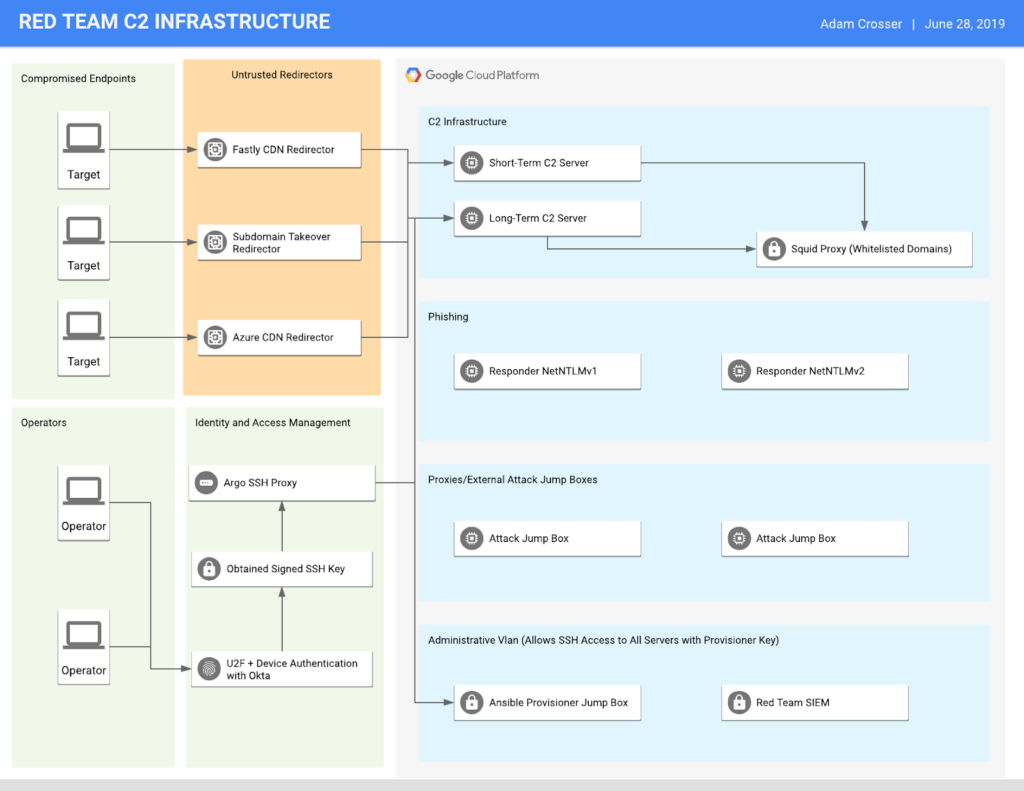
Ou encore un autre exemple provenant de cet article (qui montre comment avoir une infrastructure sécurisé vis à vis des données qui peuvent y transiter):
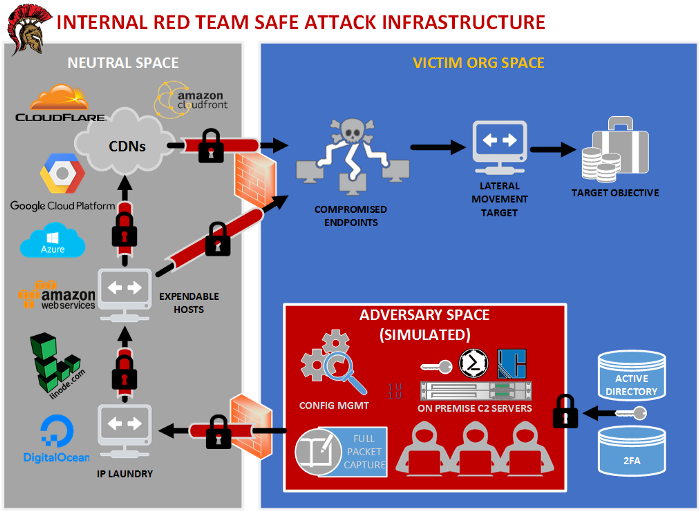
Conclusion
Afin de mener au mieux une offensive, il est indispensable de se munir d’une infrastructure capable de supporter chacune des phases de l’attaque. Pour cela, l’infrastructure se centre sur le C2, celui qui contrôle les machines compromises, auquel viennent s’adjoindre un certain nombre de serveurs comme les redirecteurs par exemple, pour gagner en résilience et en discrétion. En plus de prévoir un confort suffisant pour les opérateurs, elle permet aussi d’augmenter le réalisme de l’engagement pour se rapprocher au plus de ce que les acteurs malveillants sont capables de produire. J’espère que cet article vous aura plu, et je vous invite à aller consulter tout les autres postes de blog que j’ai pu mentionner, chacun d’eux vous permettra d’approfondir ce qui a été développé ici!
La plupart des informations de cet article sont issues de ce répo github qui a été d’une aide précieuse.
